서론
JavaScript: 추가 학습
- AJAX - 비동기 프로그래밍 (프론트엔드, 백엔드 – 공통사항)
요즘 회사 : Angular, jquery Vercel - GitHub 통째로 올리고 배포 가능
기초 때는 Vanilla로 하는 것 좋음 처음에 너무 high-level(trend)만 배우면 안 좋다 (쓰기 편해서 사용하는 기술들임)
면접 볼 때 단어 (프론트엔드 해봤다) 얘기하지 말고 이런 것을 만들었다/이런 문제를 해결했다 “어린애처럼 얘기하기” e.g. 프로젝트 만드는데 CRUD 사용했고, React를 사용해서 app을 만들었다, etc.
주제. Python
- 파이썬 설치, 라이브러리 설치
- 개요
- 문법 (변수, 자료, 연산자 등)
- Numpy, Pandas, Matplotlib
- Flask를 통해 DB 연결 맛보기
Linux에서 Python이 기본으로 설치되어 있음
Python 3.6 이상 설치 (latest as of 0731: 3.11)
Python 설치 확인

pip install numpy pandas matplotlib jupyter
numpy
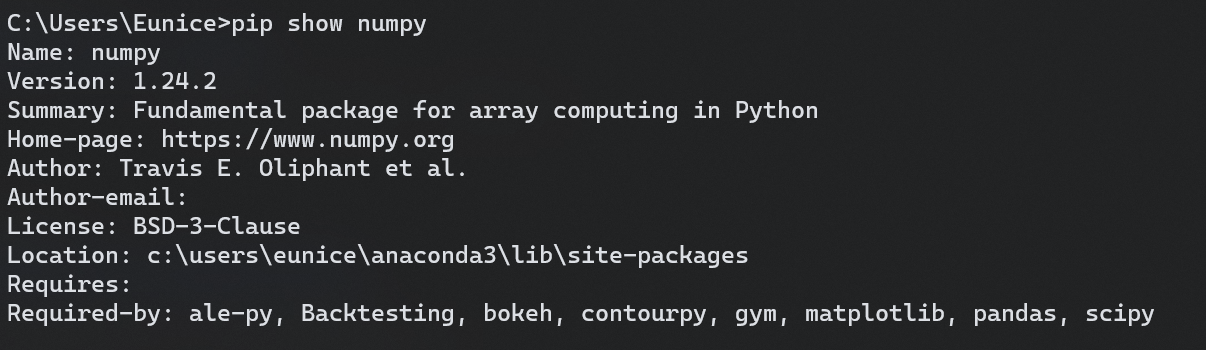
pandas
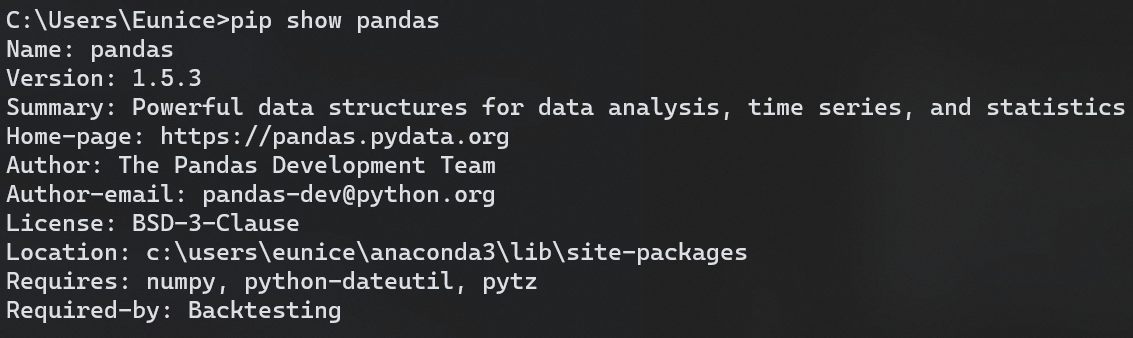
matplotlib
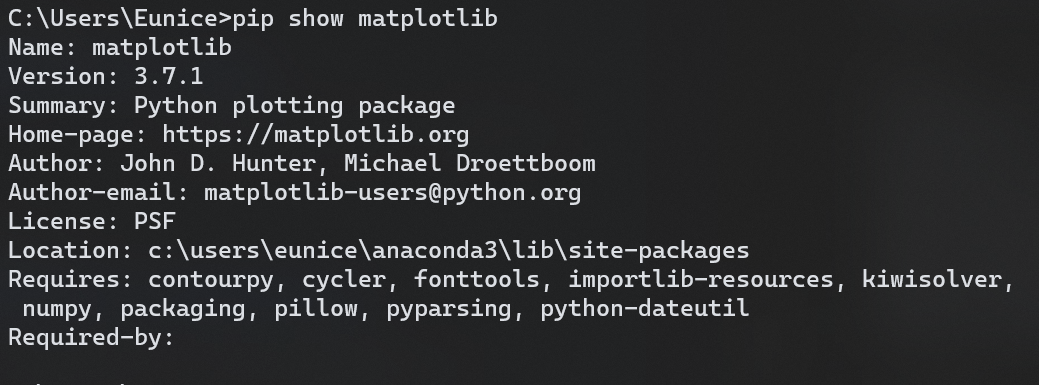
jupyter
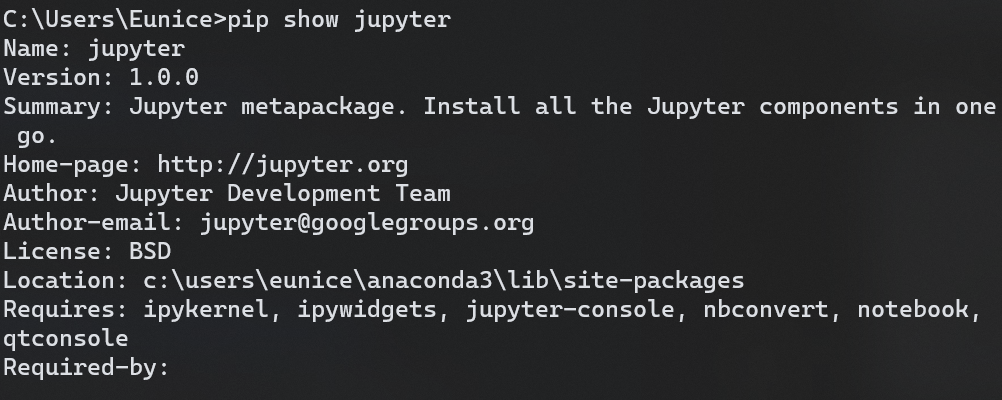
Python 개요
-
Standard Module (표준 모듈)
- Numpy : 수학/통계, 데이터 기반 (표준편차, median, etc.)
- Pandas : 테이블 데이터 (Dataframe) 다루도록 하는 라이브러리 (SQL, DB)
- Matplotlib : 데이터 시각화 (e.g. 차트, etc.)
- Jupyter : 실습 – 파이썬의 유용한 툴, 웹서버가 실행해서 안에서 코드 작성 할 수 있도록 (데이터 분석, 수학자/과학자 사용)
- 머신러닝 서버를 Jupyter로 만들 수 있음 (inference 가능)
- Tensorflow : 딥러닝, neural network 알고리즘 가장 쉽게 이해하고 구현할 수 있는 라이브러리
- 인공지능이 대세 : 99% Python, 1% C (CUDA/GPU 프로그래밍)
- Math : 수학적 계산을 돕는 함수들을 포함한 라이브러리
-
활용분야: 웹 개발, 데이터 분석, 기계 학습, 인공 지능 등
Jupyter 활용
VS Code에서 Shift+Enter > Python 환경 > 설치된 파이썬 버전 선택
Python 기초
- 변수와 데이터 타입
- 연산자와 표현식
- 문장과 제어 흐름
- 함수와 모듈
- 데이터 구조와 컬렉션
- OOP (객체지향 프로그래밍)
- Numpy 초급
- Pandas 초급
- Matplotlib 초
- Flask
파이썬을 스스로 학습하 적이 있어서 이 중에 제가 어려워하는 부분을 중심으로 학습하겠습니다. 하나하나씩 주피터 코드 내용을 훌터봐서 정리하자면 …
- 데이터 구조와 컬렉션에서 ‘List’, ‘Tuple’, ‘Set’, ‘Dictionary’
- OOP에서 클래스와 객체, 상속 (부모 클래스, 자식 클래스)
- Numpy, Pandas, Matplotlib, Flask (5번부터 10까지)
Module 가져오기
import [library_name] as [alias]
모듈명을 파이썬 파일의 이름을 기준으로 사용한다.
e.g. my_module.py 파일이 있으면
def say_hello(name):
print(name + "님, 안녕하세요!")
def get_fullname(last_name, first_name):
full_name = last_name + " " + first_name
return full_name
def add_numbers(a, b):
sum = a+b
return sum
import my_module로 가져올 수 있습니다. 또는 from my_module import say_hello 모듈 파일 안에 있는 함수 또는 모듈의 일부 코드를 가져올 수 있습니다.
TEST
from my_module import say_hello, get_fullname, add_numbers
from your_module import get_fullname
full_name = get_fullname("David", "Paul")
print("Your full-name is {}".format(full_name))
이슈. 똑같은 함수 하나(get_fullname)가 두 가지 모듈 안에서 정의되어 있는데
실행해도 출력이 안되는 상황이 발생되었다.
설명.
- Jupyter는 Web UI처럼 실행됨.
- your_module이라는 파일은 미리 만들었으니까 있는 것을 알고 있음.
- 단, 실행할 당시에 your_module 안에 있는 함수가 인식이 안 됨.
- 해결 방식 : 재시작/재실행
NOTE. 인공지능과 Jupyter 인공지능은 프로그래밍이 아닌 실험이다. 코드는 수단일 뿐. 인공지능에서 jupyter를 많이 사용한다.
Lists
- 리스트는 순서가 있는 변경 가능한 요소의 집합입니다.
List Traversal
fruits = ["사과", "바나나", "체리", "파인애플"]
# first element in list
print("첫 번째 과일:", fruits[1])
# last element in list
print("마지막 과일:", fruits[-1])
# 첫 번째 과일: 바나나
# 마지막 과일: 파인애플
List에 원소 추가 및 삭제 - append, remove
# 원소 추가
fruits.append("포도")
print("갱신된 과일:", fruits)
# 갱신된 과일: ['사과', '오렌지', '체리', '파인애플', '포도']
# 원소 삭제
fruits.remove("체리")
print("갱신된 과일:", fruits)
# 갱신된 과일: ['사과', '오렌지', '파인애플', '포도']
List 원소 변경
fruits[1] = "오렌지"
print("변경된 과일:", fruits)
# 갱신된 과일: ['사과', '오렌지', '파인애플', '포도']
Tuples
- 튜플은 순서가 있는 변경할 수 없는 요소의 집합입니다.
- 메모리 사용량이 적다
person = ("Alice", 25, "뉴욕")
print("사람:", person)
# 사람: ('Alice', 25, '뉴욕')
print("이름:", person[0])
print("나이:", person[1])
# 이름: Alice
# 나이: 25
Tuple Casting
a = tuple(a)
Sets
- 세트는 ==순서가 없는== 고유한 요소의 집합입니다.
numbers = {1, 2, 3, 4, 4, 4}
print("숫자:", numbers)
Set 원소 추가 - add
numbers.add(5)
print("갱신된 숫자:", numbers)
# 갱신된 숫자: {1, 2, 3, 4, 5}
numbers[0]
ERROR.
---------------------------------------------------------------------------
TypeError Traceback (most recent call last) [~\AppData\Local\Temp/ipykernel_57072/4266639200.py](https://file+.vscode-resource.vscode-cdn.net/c%3A/Users/Eunice/OneDrive%20-%20Sogang/%EB%B0%94%ED%83%95%20%ED%99%94%EB%A9%B4/AI_%EC%9B%B9%EA%B0%9C%EB%B0%9C_NIPA/Seoul-ICT-Web-Base/python/~/AppData/Local/Temp/ipykernel_57072/4266639200.py) in ()
----> 1 numbers[0]
TypeError: 'set' object is not subscriptable
“not subscriptable” == 셀 수 없다
Dictionary
- 딕셔너리는 키-값 쌍(key-value pair)의 순서가 없는 집합입니다.
print("이름:", student["name"])
ket를 날리는 방법
del student["age"]
print("갱신된 학생:", student)
# 갱신된 학생: {'name': 'Alice', 'major': '수학'}
OOP
클래스와 객체 : 생성자(constructor), 메서드(method/함수)
- class 이름 – 대문자로 시작 (e.g. Rectangle)
# 클래스와 객체
# 클래스는 객체를 생성하기 위한 청사진(blueprint)이며, 객체는 클래스의 인스턴스입니다.
# 클래스 정의하기
class Rectangle:
#생성자(constructor)
def __init__(self, width, height):
self.width = width
self.height = height
# 메서드(method, 함수)
def area(self):
return self.width * self.height
# Object creation
# instance
rect1 = Rectangle(3, 5)
#rect2 = Rectangle(4, 6)
# Accessing object attributes and methods
print("Rectangle1 width: {}".format(rect1.width))
print("Rectangle1 height: {}".format(rect1.height))
print("Rectangle 1 area:", rect1.area())
#print("Rectangle 2 area:", rect2.area())
생성자 - 객체/instance를 (생성하고) 초기화하는 메서드
메서드 - 클래스 안에 선언된 함수
Class vs. Instance vs. Constructor
- Class
- describes structure of instance (e.g. behavior, information)
- Instance
- object created from class
- 메모리 공간을 차지하는 객체
- Constructor
- method in a class used to create and initialize an object of a class
객체지향 언어에서 많이 언급하는 개념
- Constructor Overloading
- Constructor Overriding
Constructor 선언
def __init__(self):
self.property = None;
...
특징 포인트 : 앞과 뒤 언더바 2개씩, init, argument로 self self : 자기 자신을 포인트/참고 한다
학교에서 Java를 공부했을 때 Class, Instance, Constructor 등의 개념을 배웠지만… 아직도 이해하기가 어렵네요… 따로 유데미 강의를 통해서 또는 스스로 인터넷 검색을 통해서 더욱 깊이 실펴볼 필요가 있다. 개념 파악하고 파이썬에서 사용하는 방식을 배워서 숙지할 것!
NEXT. 상속
Python Library 정리 ~~
## Numpy docs. https://numpy.org/doc/stable/reference/
- 배열
- 배열 요소 접근 -
arr[i],arr[i, j] - 배열 생성 -
np.array - 배열 속성 -
np.shape,np.dtype - 배열 함수 -
np.sum,np.mean,np.max,np.min - 배열 재구성 -
np.reshape - 배열 슬라이싱 -
arr[n:m] - 배열 연결 -
np.concatenate - 배열 스택 -
np.stack - 난수 생성 -
np.random.rand(row, col)
- 배열 요소 접근 -
Pandas
docs. https://pandas.pydata.org/docs/reference/index.html
- DataFrame 생성
- 데이터 접근
- 요약 통계량
- 데이터 필터링
- 열 추가 및 삭제
- CSV 파일로부터 읽기
Matplotlib
docs. https://matplotlib.org/stable/api/index.html
Matplotlib 가져오기
import matplolib.pyplot as plt
- 산점도(Scatter Plot) -
plt.scatter(x, y) - 막대 그래(Bar Graph) -
plt.bar(x, y) - 히스토그램(Histogram) -
plt.hist(data) - 파이 차트(pie chart) -
plt.pie(...)
Flask
docs. https://flask.palletsprojects.com/en/2.3.x/
Flask는 파이썬 기반의 프레임워크인데 SQL 데이터베이스를 쉽게 만들고 관리할 수 있는 기능을 제공하고 있는 프레임워크입니다.
과제
- 숫자끼리 비교하는 연산과 문자끼리 비교하는 연산 중 왜 문자끼리 비교하는 연산이 상대적으로 불리한지 이유에 대해서 정리해보고 샘플 코드를 구현해서 제출하기
source. https://github.com/ganyunhee/ai_webdev/tree/main/python/compare_num_char
- 파이썬으로 일부 중복되는 element를 저장하고 최소 element가 10개이상 되는 배열을 만든다. 그리고 set() 구문 없이 오로지 for in 문으로 배열의 중복된 값을 없애는 코드를 작성하기
source. https://github.com/ganyunhee/ai_webdev/tree/main/python/repeating_char
- 자기 컴퓨터에 mysql 데이터베이스 설치하기 + HeidiSQL 또는 Dbeaver 프로그램을 설치한 후 mysql을 localhost로 호스팅되는 것 까지 세팅하기
HeidiSQL 설치 [DONE]
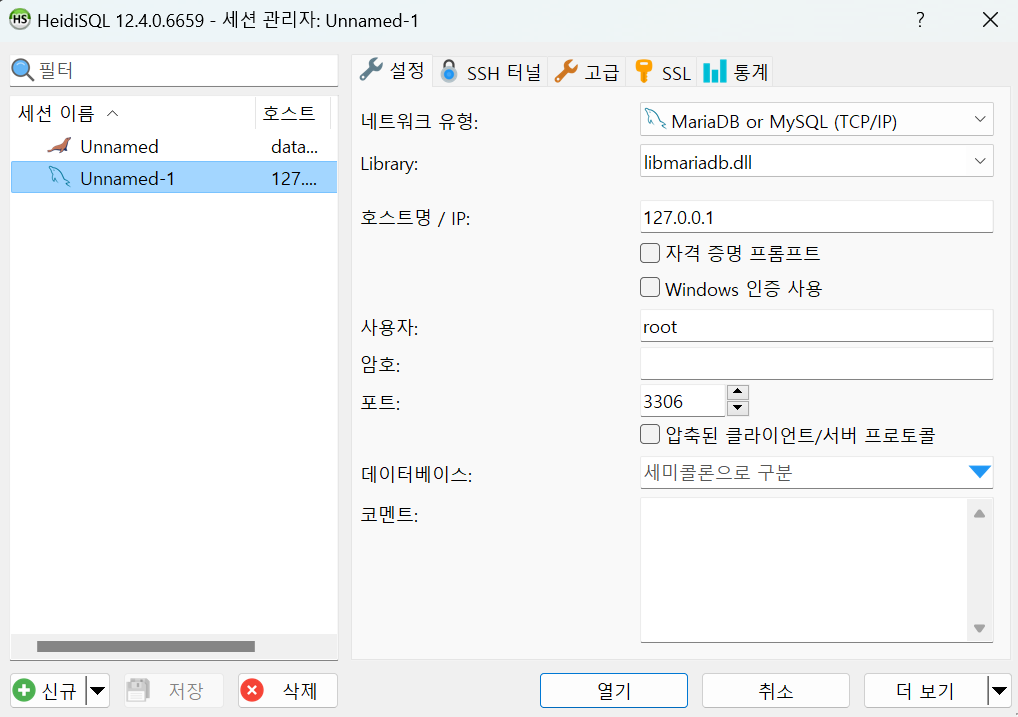
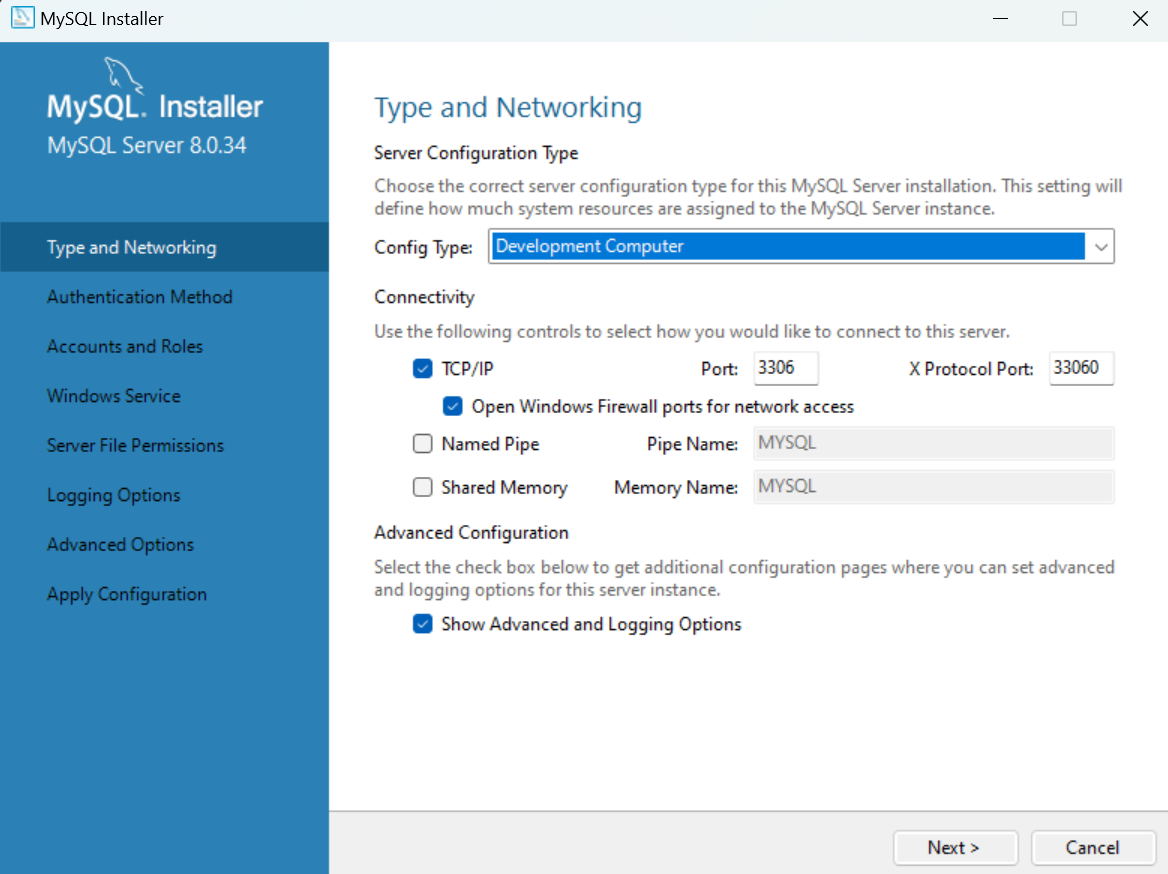
MySQL 설치
Full Installation via MSI Installer
> ref. https://dev.mysql.com/downloads/installer/
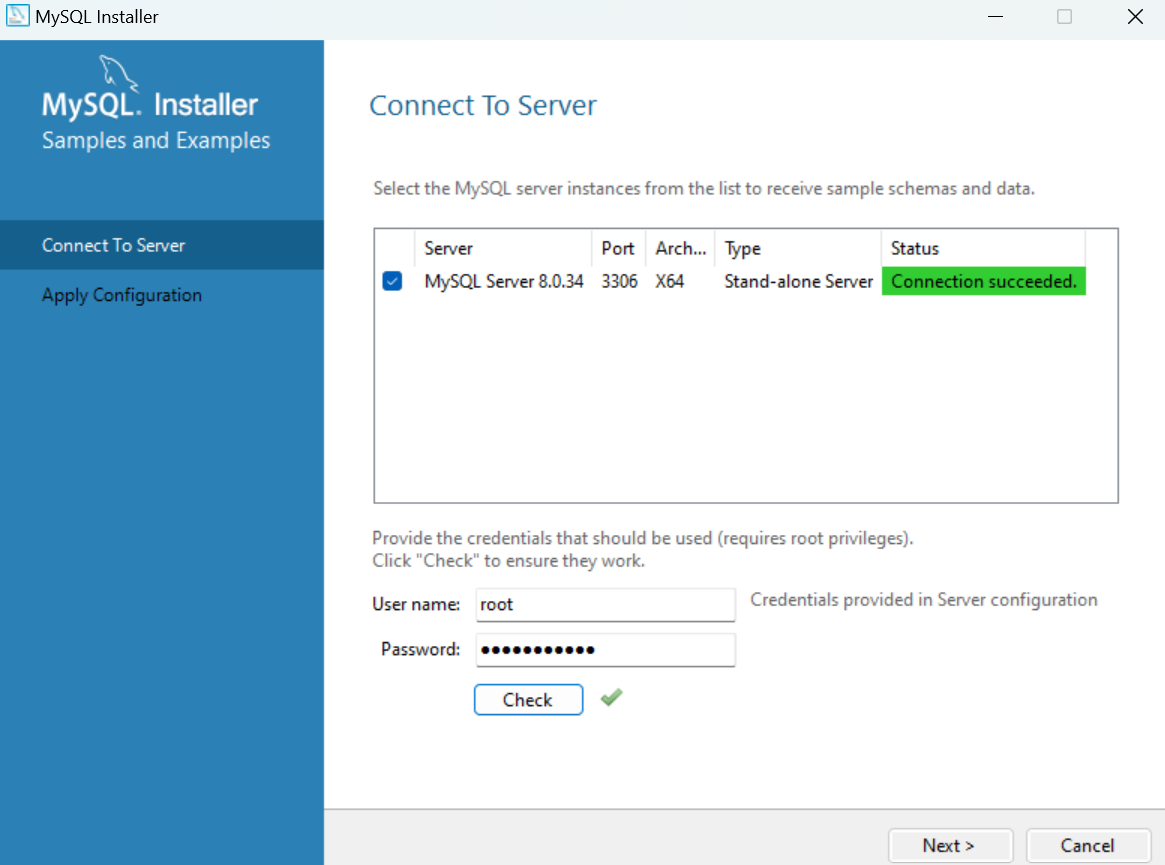
MySQL을 localhost로 hosting
> ref 1. Connecting to the MySQL Server Using Command Options.
https://dev.mysql.com/doc/refman/8.0/en/connecting.html
> ref 2. Setup a Local MySQL Database.
https://ladvien.com/data-analytics-mysql-localhost-setup/
——————————————————————————
본 후기는 정보통신산업진흥원(NIPA)에서 주관하는 <AI 서비스 완성! AI+웹개발 취업캠프 - 프론트엔드&백엔드> 과정 학습/프로젝트/과제 기록으로 작성 되었습니다. #정보통신산업진흥원 #NIPA #AI교육 #프로젝트 #유데미 #IT개발캠프 #개발자부트캠프 #프론트엔드 #백엔드 #AI웹개발취업캠프 #취업캠프 #개발취업캠프